Using Runpandas to explore Nike Run Activity Data
How to download and analyze your Nike Run activities using NRC-Export and Runpandas



My wife started to run seriously since last year and used the Nike Run app to track her runs. Unfortunately, there isn't an open API to get the data and get advanced analytics on her activities. So she asked me, if there was a way to perform some analysis on her own. At this tutorial, I will show how I fetched the data from Nike Run social app. Then, I will show how I explored that data using Python and RunPandas. Even this article is focused specifically on Nike Run activities, it will be useful for anyone interesteing in learning more about how get your running data and play with it.
There are three things you will need up front.
- A Nike Run member account
- A environment to run Python.
- To start, I will assume you have a Nike Run account with at least one activity logged.
There is a commandline program called nrc-exporter that automates the data export to a local directory. We will use it here. The first step, is to use the terminal and install the package using pip package installer.
pip install nrc-exporterTo start using you will need the the authentication token that you can get when you login at the Nike Web account. Here are the steps:
- Login into your Nike account;
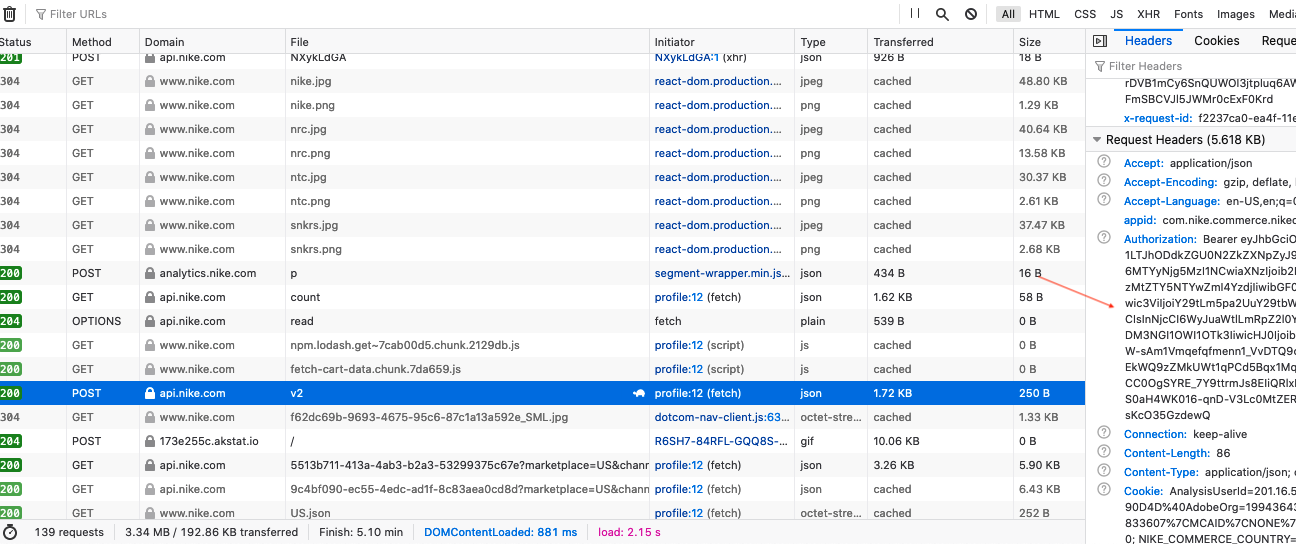
- Open the developer tools -> Application. Then, you need to copy the token (Authorization field) as shown at the image below:
At your terminal, just execute the nrc-exporter with the given token as shown below:
nrc-exporter -t tokenYou will see the screen below after running the tool:
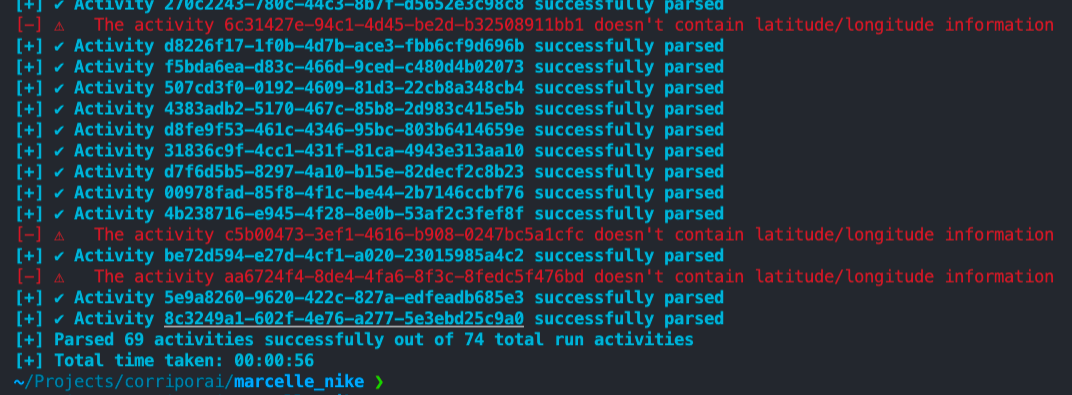
All your running data will be downloaded to a folder named activities from where you executed the script. All the activities are in JSON format. If this step did not work for you, you can see other alternatives at the website of the owner of the tool nrc-exporter. Take a look there!
In this section, I will walk you through how I used Runpandas, a library focused on running data exploratory analysis, to answer some questions that she asked me to look into:
- Have my runs gotten faster over time?
- Is my max speed higher on shorter runs?
- Do I run longer distances on the weekend than during the week?
- Do I run faster on the weekend than during the week?
- How many days do I rest compared to days I run?
- How many kilometers did I cover ?
- Which month of the year do I run the fastest?
- Which month of the year do I run the longest distance?
- How has the average distance per run changed over the years?
- How has the average time per run changed over the years?
- How has my average speed per run changed over the years?
- Am I ready for a half-marathon? What would it be my finishing time ?
Now, to get the data into a table, I’ll fun the following code. To read the json directory, you can run the runpandas.read_dir_nikerun method to create a Runpandas Activity Dataframe combining the workouts as individual rows . If you are unfamiliar with Pandas or Runpandas, consider them as Excel tables.
#Disable Warnings for a better visualization
import warnings
warnings.filterwarnings('ignore')
import runpandas as rpd
session = rpd.read_dir_nikerun('./data/nikerun_data/')
The data frame sessions holds the all the running data from the nike_run_session directory. Let’s look at some of the data.
session
By calling sessions.columns, I can see this list of features included in our dataset. NikeRun provides interesting columns such as calories, steps, altitude, heart rate, latitude and longitude. We are missing some valuable data such as speed, pace and the moving time.
session.columns
Runpandas provides special accessors that extends the capabilities of Pandas library. For sesssions we have the runpandas.types.acessors.session._SessionAcessor with several methods that computes these running metrics for all of our activities included in the DataFrame.
#In this session we compute the distance and the distance per position across all workouts
session = session.session.distance()
#comput the speed for each activity
session = session.session.speed(from_distances=True)
#compute the pace for each activity
session = session.session.pace()
#compute the inactivity periods for each activity
session = session.session.only_moving()
session
Now that I have the data I want I’m ready to start doing some visualization and analysis.
The first question to answer is to see how many activities that my wife ran from 2020 until now (2021). The method runpandas.types.acessors.session._SessionAcessor.count answers exactly this question.
print('There are ', session.session.count(), ' activities available in this session.')
But if we need to performa deeper analysis over all activities, it would be necessary a lot of conversions and aggregations to perform an overall analysis. Runpandas has a special method runpandas.types.acessors.session._SessionAcessor.summarize that summarizes all statistics for all activities, and it drastically simplifies further processing.
summary = session.session.summarize()
summary
We have all the main statistics required our downstream analysis. Each row includes the the running summary . Let’s look at some of the data:
print(
summary[['total_distance', 'ellapsed_time']]
.sample(5)
.sort_index()
.to_string(formatters={
'total_distance': '{:.0f}m'.format,
}))
This shows five randomly selected rows from the data frame. Let us find out over which time period these activities were recorded:
first_date = summary.index.min()
last_date = summary.index.max()
print('Activities recorded from %s to %s, total of %d days.' % (
first_date.strftime('%Y-%m-%d'),
last_date.strftime('%Y-%m-%d'),
(last_date - first_date).days))
One year of training! We must remember that the data shows only the activities that were recorded on Nike Run.
summary['days_diff'] = summary.index.to_series().diff().dt.days
summary['total_distance'] = summary['total_distance'] / 1000 #conver meters to kms
summary['mean_speed'] = summary['mean_speed'] * 3.6 #convert to km/h
print('Period:', (summary.index.max() - summary.index.min()).days, 'days')
print('Total activities:', len(summary), 'activities')
print('Kms total:', summary.total_distance.sum())
print('Interval between two runs (average)):', round(summary.days_diff.mean(),2), 'days')
print('Average Pace (min/km):', summary.mean_pace.mean())
print('Average Distance (km):', round(summary.total_distance.mean(),2))
We also got some basic statistics using the pandas aggregation methods such as mean, sum, max and min. As you can see above, my wife ran 67 times with a total distance of 458kms in an interval range of 5 days between runs and a average pace of 06:29' min/km and an average distance of 6.84kms.
what were the top three activities in which she covered the longest distance?
print(
(summary['total_distance'] /1000).nlargest(3)
.to_string(float_format='%.1fkm'))
And what were the top three activities on which she spent the most time?
print(
(summary['ellapsed_time']
.nlargest(4))
.to_string(float_format='%.1fh'))
What is her average time and distance per day on trainnings ?
print(
summary[['total_distance', 'ellapsed_time']]
.mean()
.to_frame('mean')
.T)
Apparently she covers about 6.8km and 44min per day on average—during activities she recorded.
With Pandas, we can also group and aggregate data to other periods of time. For example, let’s find the day/month/quarter/year for each activity in which she covered, and see the total distance, average speed and number of trainings. We will decompose the timestamp in Month, Week, Weekday, Year and YearMonth.
import pandas as pd
summary = summary.assign(Year=summary.index.year, Month=summary.index.month, Week=summary.index.week, Weekday=summary.index.weekday)
summary['Year-month'] = pd.to_datetime(summary[['Year','Month']].assign(day=1)).dt.to_period('M')
summary['Year-week'] = summary.index.strftime('%Y-w%U')
summary
Now we can aggregate and plot some charts using matplotlib package to see her training over the computed periods.
import matplotlib.pyplot as plt
fig, axr = plt.subplots(3,1, figsize=(14,14 ))
ticks = summary.groupby(summary['Year-month']).agg({'total_distance': 'sum'}).index.astype('str').to_list()
axr[0].bar(summary.groupby(summary['Year-month']).agg({'total_distance': 'sum'}).index.astype('str'),
summary.groupby(summary['Year-month']).agg({'total_distance': 'sum'}).values.flatten(),
yerr=summary.groupby(summary['Year-month']).agg({'total_distance': 'std'}).values.flatten(),
tick_label=ticks, label='Number of kilometers')
axr[0].set_title('Total number of kilometers')
axr[0].set_ylabel('Km')
summary.boxplot(['mean_speed'], by='Year-month', ax=axr[1])
axr[1].set_xticklabels(ticks)
axr[1].set_ylabel('Km/h')
summary.groupby('Year-month')['mean_speed'].count().plot.bar(ax=axr[2], color='C1')
axr[2].set_xticklabels(ticks)
axr[2].set_title('Number of trainings')
plt.show()
fig, axr = plt.subplots(3, figsize=(14,14), sharex=True)
summary.boxplot(['mean_speed'], by='Year-week', ax=axr[0])
axr[0].set_ylabel('Km/h')
summary.groupby('Year-week')['total_distance'].sum().plot.bar(ax=axr[1])
axr[1].set_title('Total number of kilometers')
axr[1].set_ylabel('Km')
summary.groupby('Year-week')['mean_speed'].count().plot.bar(ax=axr[2], color='C1')
axr[2].set_title('Number of trainings')
plt.show()
weekdays = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
fig, axr = plt.subplots(3, figsize=(14,14))
summary.groupby('Weekday')['total_distance'].sum().plot.area(ax=axr[0])
axr[0].set_title('Total number of kilometers')
axr[0].set_ylabel('Km')
axr[0].set_xticks([0,1,2,3,4,5,6])
axr[0].set_xticklabels(weekdays)
summary.boxplot(['mean_speed'], by='Weekday', ax=axr[1])
axr[1].set_ylabel('Km/h')
axr[1].set_xticks([0,1,2,3,4,5,6])
axr[1].set_xticklabels(weekdays)
summary.groupby('Weekday')['mean_speed'].count().plot.area(ax=axr[2], color='C1')
axr[2].set_title('Number of trainings')
axr[2].set_xticklabels(weekdays)
axr[2].set_xticks([0,1,2,3,4,5,6])
plt.show()
Conclusions until now from the plots above:
- The month that she ran more kms was December 2020. It corresponds to the number of the trainings also in the same month: 8 activities.
- Her Average speed didn't improve over the years, but the boxplots present from February 2021 until now a smaller variation over the mean.
- She trains one or twice a week. For a beginner the volume is ok, but not for someone training for a marathon.
- The day of the week that she runs a lot is on Sundays and then Fridays. Sunday is a rest day for her from her job, so it makes sense, more time for training!
Does she run longer distances on the weekend than during the week? Let's evaluate it by applying some pandas grouping functions. The idea is to aggregate over the weekday column.
import numpy as np
summary['ellapsed_time_minutes'] = summary['ellapsed_time'] / np.timedelta64(1, 'm')
summary['count'] = 1
summary_by_day = summary.groupby([pd.Grouper(freq='D', level=0)]).sum()
weekdays = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
summary_by_day[['total_distance', 'ellapsed_time_minutes', 'count']].groupby(lambda d: weekdays[d.weekday()]).mean().agg(['idxmax', 'max']).T.unstack(level=0).swaplevel(1)
The answer above corresponds to what we interpreted from the plots, she runs most of time and distance on Sundays!
We can do the same for the months of the year:
months = 'Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec'.split()
summary_by_month = summary.groupby([pd.Grouper(freq='M', level=0)]).sum()
summary_by_month[['total_distance', 'ellapsed_time_minutes', 'count']].groupby(lambda m: months[m.month-1]).mean().agg(['idxmax', 'max']).T.unstack(level=0).swaplevel(1)
December was the month of the year in which she does most of her running on average
Another question she asked was if she started running faster, on average, over the past few months? To answer this question, I will plot the relationship between date and average pace, to see any trend.
#let's convert the pace to float number in minutes
import datetime
summary['mean_moving_pace_float'] = summary['mean_moving_pace'] / datetime.timedelta(minutes=1)
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
plt.subplots(figsize=(8, 5))
plt.plot(summary.index, summary.mean_moving_pace_float, color='silver', label = 'average pace')
#add trend line
x = np.asarray(summary.index) #convert data to numpy array
x2 = mdates.date2num(x)
y = np.asarray(summary.mean_moving_pace_float)
z=np.polyfit(x2,y,1)
p=np.poly1d(z)
plt.plot(x,p(x2),'r--')
#format the figure and display
fig.autofmt_xdate(rotation=45)
fig.tight_layout()
fig.show()
plt.title("Pace Evolution")
plt.xlabel("Runnings")
plt.ylabel("Pace")
plt.legend()
There isn't a indication of improvement over time, The change is a little , with a little increase over the time (trend line). But could it be the distance ,how far she runs , she slows down ? Let's see the correlation. The following code will create a regression plot of her average speed vs distance.
#Seaborn is a data visualization library.
import seaborn as sns
sns.set(style="ticks", context="talk")
sns.regplot(x='total_distance', y = summary.mean_moving_speed * 3.6, data = summary).set_title("Average Speed vs Distance")
There is not relationship as we can see from the data above, from the total distance vs moving speed, by the way, even in far distances she maintains the velocity. How about her my max speed higher on shorter runs? Is it true ? She performs on friday several shorter runs. Let's see through data:
sns.scatterplot(x='total_distance', y = summary.max_speed, data = summary).set_title("Max Speed vs Distance")
There are some outliers,let's remove them. Maybe due to some incorrect calculation or record registering.
summary_without_outliers = summary[summary['max_speed'].between(1,15)]
sns.regplot(x='total_distance', y = summary_without_outliers.max_speed, data = summary_without_outliers).set_title("Max Speed vs Distance")
Interesting that her speed improved as the total distance grew, which shows that long distances don't affect her performance. She is probably a long runner!
How has the average distance, time and speed per run changed over the years? Let's see the plots over the year axis.
import matplotlib.pyplot as plt
fig, axr = plt.subplots(3,1, figsize=(14,14 ))
ticks = summary.groupby(summary['Year']).agg({'total_distance': 'sum'}).index.astype('str').to_list()
axr[0].bar(summary.groupby(summary['Year']).agg({'total_distance': 'sum'}).index.astype('str'),
summary.groupby(summary['Year']).agg({'total_distance': 'sum'}).values.flatten(),
yerr=summary.groupby(summary['Year']).agg({'total_distance': 'std'}).values.flatten(),
tick_label=ticks, label='Number of kilometers')
axr[0].set_title('Total number of kilometers')
axr[0].set_ylabel('Km')
summary.boxplot(['mean_speed'], by='Year', ax=axr[1])
axr[1].set_xticklabels(ticks)
axr[1].set_ylabel('Km/h')
summary.groupby('Year')['mean_speed'].count().plot.bar(ax=axr[2], color='C1')
axr[2].set_xticklabels(ticks)
axr[2].set_title('Number of trainings')
plt.show()
It shows that in 2021 she is running more than 2020 at almost the same period, and that her speed improved from 2020 to 2021 (the box plot show the average is greater in 2021 and less variation). She told me that she reforced the number of trainings and the exercises she has been doing to strengthen her legs.
Which month of the year do she run the fastest?
summary[['mean_speed', 'Year-month']].groupby('Year-month').mean().agg(['idxmax', 'max']).unstack(level=0)
It was on september 2020. With the average speed of 10.1761. It was one her first best 5km, we will check this later on this post.
Finally, how much time she rest vs the time she run. We can see below that there is a 5 days interval on average between the runs, which means 1 run per week. Does it affect her performance ?
summary['days_diff'].mean()
fig,ax = plt.subplots(figsize=(8, 5))
ax.plot(summary.index, summary.mean_moving_pace_float, color='silver')
ax.set_xlabel('race')
ax.set_ylabel('pace',color='silver')
ax2=ax.twinx()
ax2.plot(summary.index, summary.days_diff,color='purple')
ax2.set_ylabel('Day without running',color='indigo', rotation=270)
plt.title('Pace vs Days without running')
plt.show()
sns.regplot(x='days_diff', y = summary.mean_moving_pace_float, data = summary).set_title("Days Diff vs Mean Pace")
No relationship between the rest days vs her pace , which means the rest day doesn't affect her pace.
Finally, I was interested in seeing her performance evolution in pace over time in 5km, 10km and 15kms. For this analysis, I had to filter the session dataframe based on distances. In this tutorial, I will assume that the distances between 5km - 5.9km , 10km - 10.9km, 15km - 15.9km will be normalized as 5, 10 , 15km.
summary_5km = summary[summary['total_distance'].between(5,5.9)]
summary_5km = summary_5km[summary_5km['mean_moving_pace_float'].between(5,8)]
summary_10km = summary[summary['total_distance'].between(10,10.9)]
summary_15km = summary[summary['total_distance'].between(15,15.9)]
fig, axs = plt.subplots(3, figsize=(18, 16))
fig.suptitle('Average Moving Pace over time (5km, 10km, 15km)')
axs[0].plot(summary_5km.index, summary_5km.mean_moving_pace_float, marker='*')
axs[0].set_title('5km')
axs[1].plot(summary_10km.index, summary_10km.mean_moving_pace_float, marker='*')
axs[1].set_title('10km')
axs[2].plot(summary_15km.index, summary_15km.mean_moving_pace_float, marker='*')
axs[2].set_title('15km')
plt.xlabel('Date')
plt.show()
Her best performance on 5km was between october 2020, but her pace kept steadily along the months. In 10kms she had an amazing improvement, with the pace reducing about 40 seconds/km. The 15km she ran only one, so we don't have further information to discuss it.
Half-Marathon is the one of the most popular races for anyone thats don't want to run the 42.195km of a full marathon and want to feel a little the taste of running half the way. Half-Marathons are quite popular and many runners even practicing for the marathon or deciding to run longer distances after the 10kms. My wife is preparing herself at the end of the year for a Half-marathon (21km) and asked me what was her predicted finishing time .
It comes to rescue machine learning techniques that can help using our historical data to predict or classify the finish time based on the distance or some variables available. There are several models to choose in order to solve this task. I will choose one of the most classical statistics models : The linear regression. Linear regression attempts to model the relationship between two variables by fitting a linear equation to observed data. One variable is considered to be an explanatory variable, and the other is considered to be a dependent variable. In our case here, we will relate the distance, the altitude to the estimated finishing time using a linear regression model.
Illustration of a linear regression model sample.
We will use the open-source library scikit-learn, it is the most useful and robust library for machine learning in Python. It provides a selection of efficient tools for machine learning and statistical modeling including classification, regression, clustering and dimensionality reduction via a consistence interface in Python. This library, which is largely written in Python, is built upon NumPy, SciPy and Matplotlib.
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
X_train = summary[['total_distance']].values
Y_train = summary['ellapsed_time_minutes']
X_test = np.array([21.0975]).reshape(1,-1)
regr = linear_model.LinearRegression()
regr.fit(X_train, Y_train)
Y_pred = regr.predict(X_test)
print('Distance: {} Km, Speed: {} Km/h, Time: {} hours \n'.format(X_test[0][0], X_test[0][0]/float(Y_pred[0]/60), Y_pred[0]/60))
We arranged all the distances as inputs and all ellapsed time in minutes as outputs and used them as training set. For testing, we want the expected finish time for the distance of 21.0975km (the half marathon official distance). We used the method regr.fit to train the model with the historical data and we asked to predict (regr.predict) the finishing time. Based on this simple model, it tell us that she will finish it in 2hrs33minutes. For a beginner it is an average finishing time, not so good, but it can get better with hard training!
plt.figure(figsize=(15,4))
plt.scatter(X_train, regr.predict(X_train)/60, label='predicted')
plt.scatter(X_test, Y_pred/60, label='predicted 21km')
plt.scatter(X_train, Y_train/60, label='historical')
plt.plot([0, X_test], [0, Y_pred/60], '--', color='C2')
plt.ylabel('Hours')
plt.xlabel('Kilometers')
plt.legend(loc='upper left')
plt.show()
- She is a weekeend long runner, and it still in preparation for running her half-marathon. More volume and training will help her to achieve her goals! For long distances there some clues that she will perform with excellent times.
There are so many ways you might explore this data. What I did above is just one example. Runpandas with other tools such as pandas, matplotlib and scikit-learn can really help you explore your running data and answer the questions that are interesting to you. Being able to captur and analyze this data open doors for any data runners that are seeking to explore their historical running activities. I hope you found this helpful and if there is anything I missed, you would like to see, or you think is incorrect, please comment below. Additionally, here are some resources you might find helpful.